My research focuses on the theory of diffusion models and reinforcement learning — from sample complexity and consistency models to RL post-training for 3D and video generation (Tencent Rhino-Bird, Meituan Longcat-Video), and increasingly on long-horizon agents and multi-agent auto-research. I created ARIS — Auto Research in Sleep, an open-source long-horizon multi-agent auto-research platform (10K+ GitHub stars, HuggingFace Daily Papers #1, VALSE 2026 talk).
He anticipates graduating in 2027 for industrial research positions and is also open to internship opportunities at any time. If you're interested, please feel free to reach out via email or WeChat (yrf13618645542).
Research Experiences
Research Intern at Meituan · Longcat-Video Team— 美团北斗人才计划 · 2025-06 – 2025-12
Research Intern at Tencent IEG— 犀牛鸟精英人才计划 (Rhino-Bird Elite Program) · 2024-03 – 2024-09
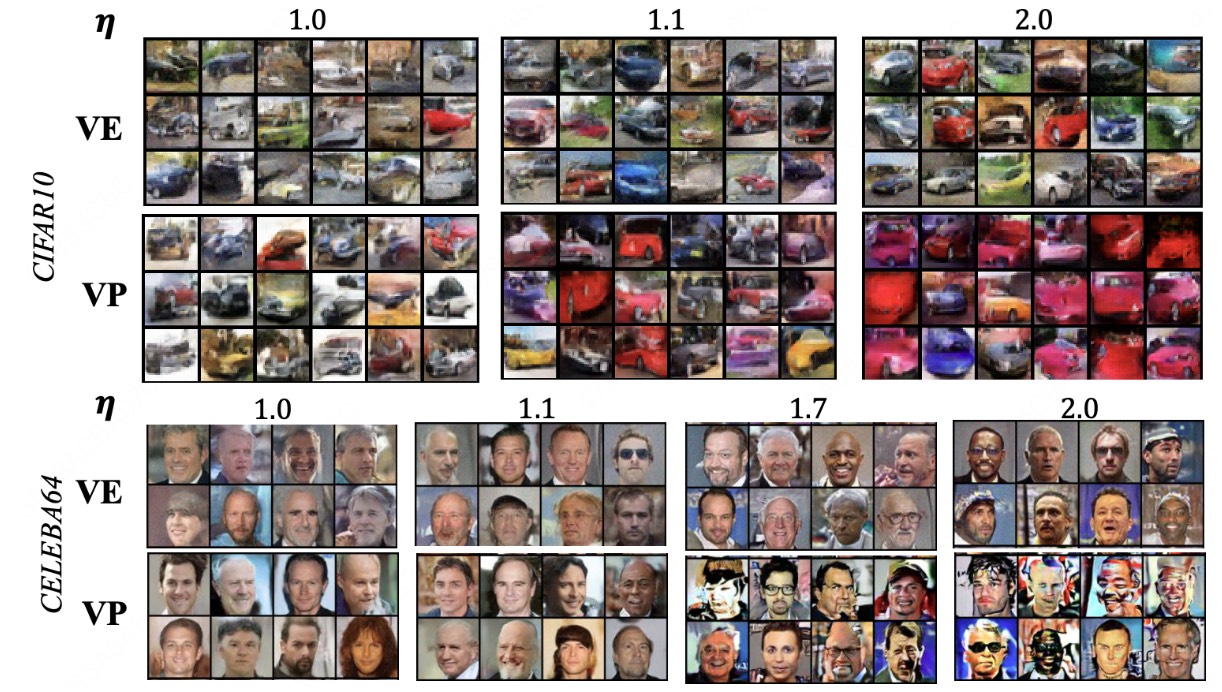
Why Rectified Flow is Better? Elucidating VP, VE, and RF-based Diffusion Models— CSML 2025, 2025
Few-Shot Diffusion Models Escape the Curse of Dimensionality— TongAI 2025 (Best Paper, 2nd Prize), 2025
ARIS — Auto Research in Sleep
Lightweight Markdown-only skills for autonomous ML research — cross-model adversarial review loops, idea discovery, and full experiment automation. No framework, no lock-in.
An open-source AI research-agent platform: a primary LLM (Claude / GPT / Kimi / …) drives the full ML research lifecycle — idea discovery, experiment design, paper writing, rebuttals — while a different-family reviewer model (e.g. GPT-5.5 xhigh via Codex MCP) adversarially audits every step. All expressed as plain Markdown SKILL.md files with zero framework lock-in.
Sub-projects:
ARIS-Code — Standalone CLI runtime — multi-provider, no Claude Code dependency required.
ARIS-Anything — Generalize the ARIS loop from 科研 to 研究 (investment DD, legal, journalism, post-mortems).
ARIS-Movie — (Upcoming) Use ARIS to generate long-form video — multi-agent narrative planning + video diffusion.
Oh-My-ARIS — (Upcoming) TUI + GUI for ARIS workflows — team-facing research platform.
Open problems explored in this line of work:
Self-Evolution Training for base models. Since every training-run produces a sequence of benchmark scores (variable feedback), this system can be used to discover new mechanisms or algorithms that improve the efficiency or performance of base models themselves.
Auto Research as the "math" task of the long-horizon agent for post-training. Treating the entire research workflow as a hard reasoning task, then post-training agents specifically on its successes.
News
2026-01Started visiting research internship at NUS School of Computing (国家留学基金委人工智能卓越专项, supervised by Prof. Xiaokui Xiao).
2026-04ARIS reached 10K+ GitHub stars; technical report featured as HuggingFace Daily Papers #1 (arXiv:2605.03042).
2026-03ARIS won AI Digital Crew Project of the Day.
2026Invited talk at VALSE 2026 on ARIS (持续学习与持续智能体分论坛).
2026Two papers at ICLR 2026 (MoE structure for diffusion; few-shot pretraining warm-up).
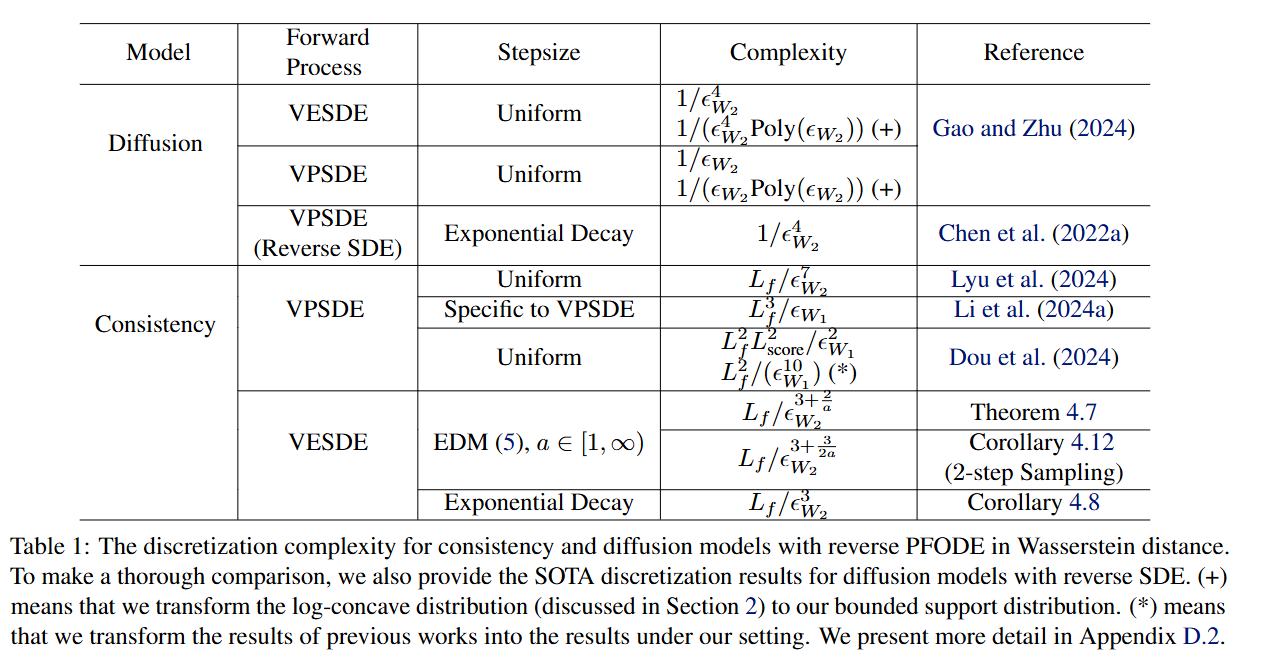
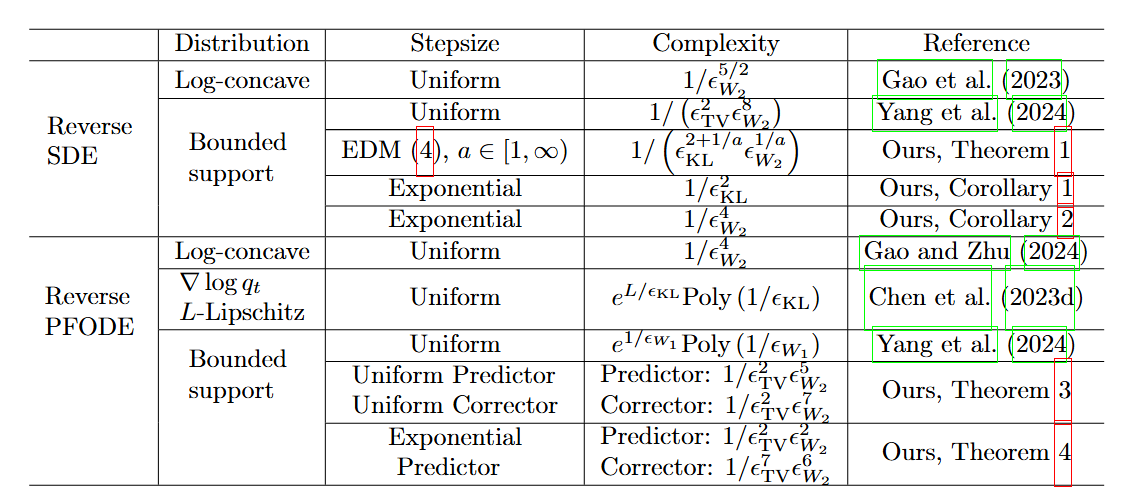
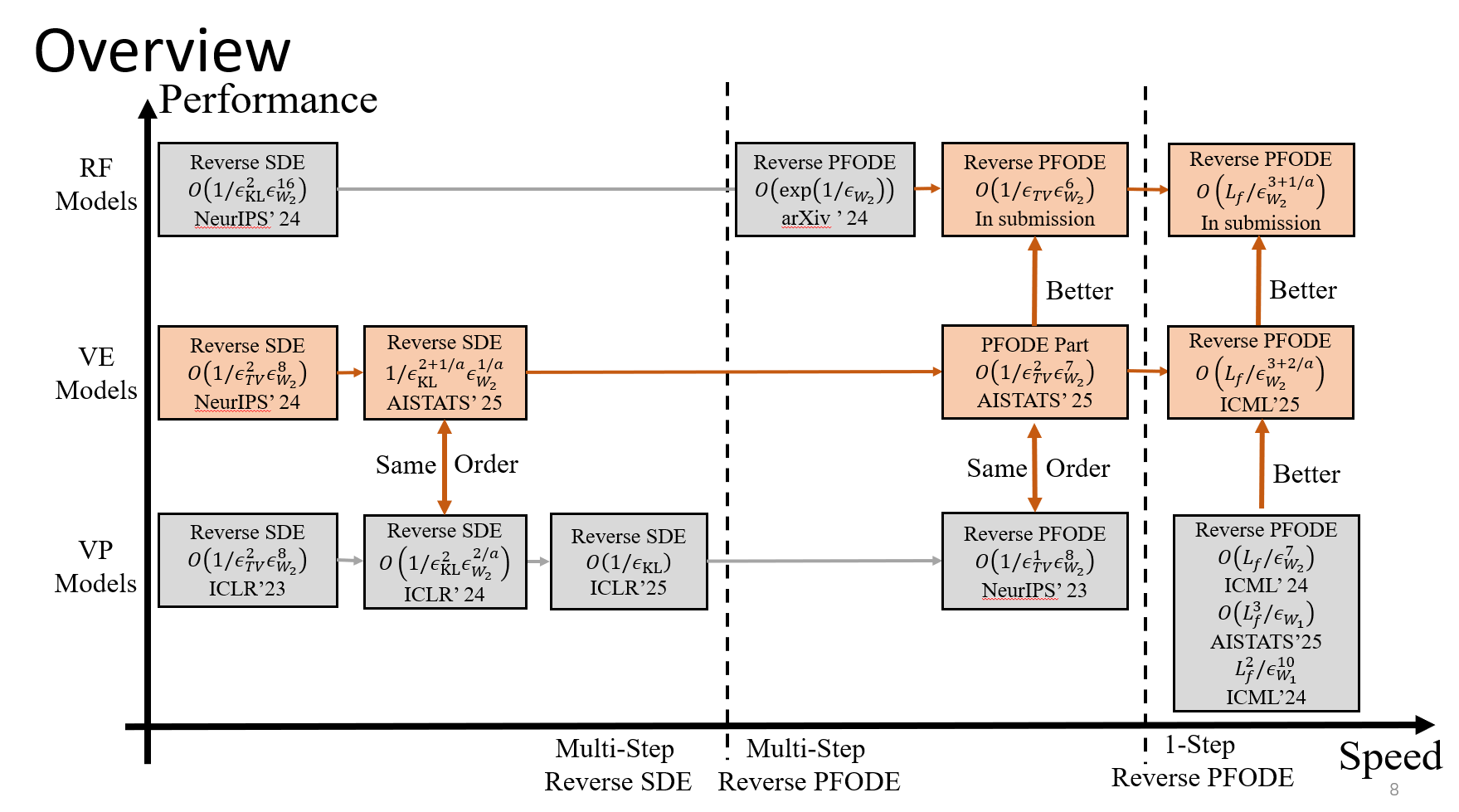
2025"Improved Discretization Complexity Analysis of Consistency Models" accepted at ICML 2025.
2025Awarded the National Scholarship for Ph.D. Students from the Ministry of Education, China.
2025Joined Meituan Longcat-Video team (北斗人才计划); co-authored DFS-GRPO (SoTA T2I post-training on UniGenBench).
Selected Publications
As we know, diffusion models can be roughly divided into pretraining, supervised fine-tuning, RL post-training, and sampling algorithm design. My works focus on these four areas, plus the long-horizon multi-agent auto-research direction.
Long-Horizon Multi-Agent Auto-Research
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
DFS-GRPO: Reward Guided Tree Search Leads to Provable Improvement in Diffusion Models
Ruofeng Yang, et al.
Preprint, in submission, 2025
Meituan Longcat-Video team. As the first work, we focused on how to efficiently train diffusion models with GRPO algorithm and proposed DFS-GRPO, which achieves SoTA performance (using FLUX.1-dev as base model, proposed in 2024/05) on UniGenBench compared with all T5-based T2I models — and ranks 5th among all open-source T2I models. We then focus on improving physical properties in video generation via post-training algorithms, plus reward modeling with V-JEPA2 / Qwen 3.5 and training-free methods.
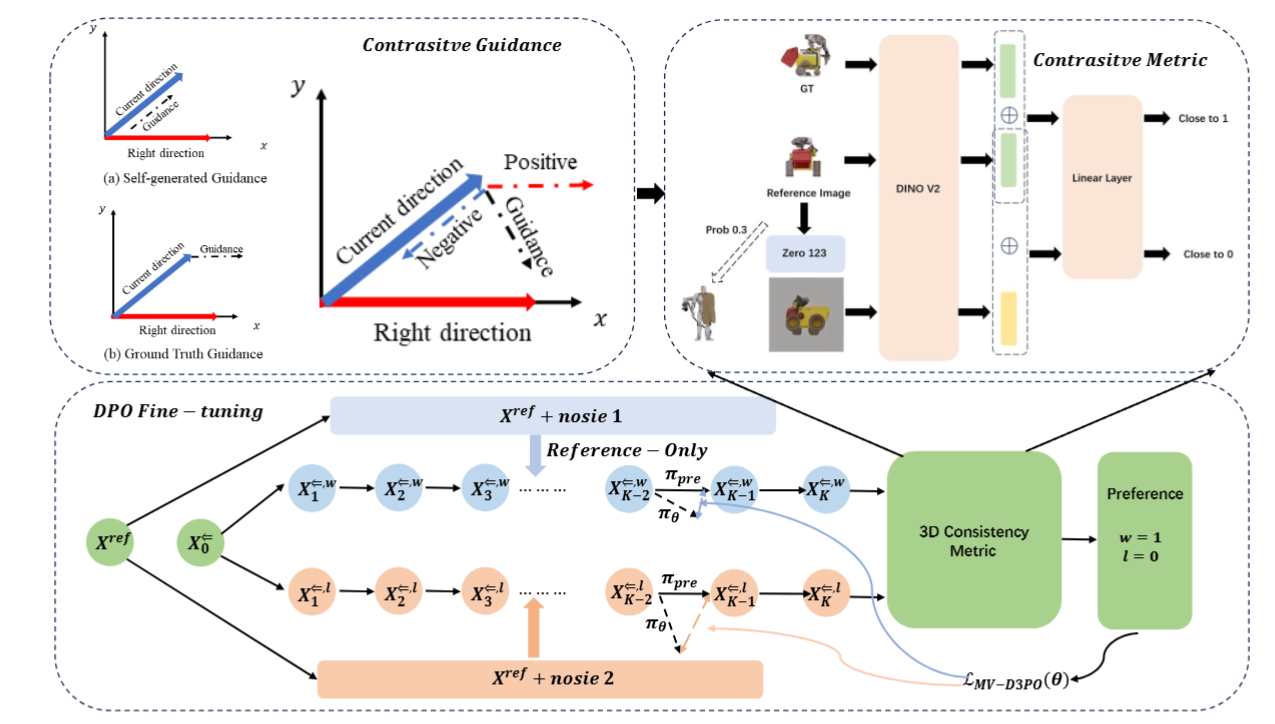
Contrastive Guidance and Feedback: A Suitable Way to Improving 3D Consistency of Multi-view Diffusion Model
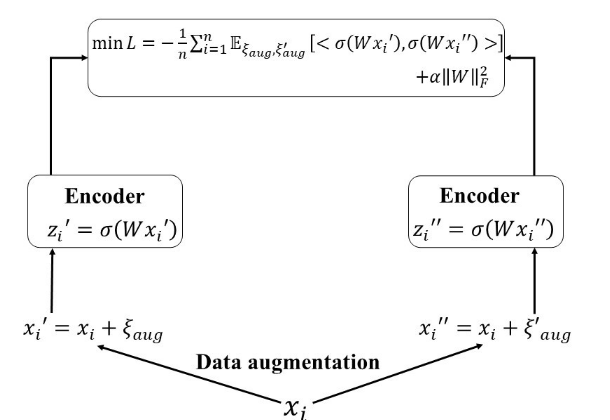
Tencent IEG · Rhino-Bird Research Elite Program. Online DPO-style algorithm with group-relative reward design. We focus on how to improve the 3D consistency of multi-view diffusion models. We first model the 3D generation process from a theoretical perspective and prove that contrastive guidance is suitable for 3D generation. Then we train a 3D consistency feedback using the contrastive method. Finally, we achieve strong performance by fine-tuning the pre-trained model with the contrastive 3D consistency feedback and the direct preference optimization (DPO) method.
Diffusion Model Sampling and Condition Generation
Improved Discretization Complexity Analysis of Consistency Models: Variance Exploding Forward Process and Decay Discretization Scheme