扩散模型 × 表征学习 × 流形学习
有一些因果在五年前就种下 —— 从 SSL objective 到流形结构的一条暗线
diffusion 天然是 SSL → 它学的表征长什么样、何时学坏 → 为何要注入外部 SSL 表征、怎么注入 → 不注入则如何用数据流形结构。
沿途:Consistency Models · VA-VAE · REPA · RAE · V-JEPA2 · JiT · 以及与 continuous DLM(ELF / DSL)的联系。
2025 年 CV 圈反复出现一个操作:把 diffusion 的中间层 / 潜空间和某个自监督(SSL)模型对齐——VA-VAE 把 latent 对齐 DINOv2、REPA 把 DiT hidden 对齐 DINOv2、RAE 干脆在 SSL 潜空间里训 decoder。但这不是凭空冒出的新风口,而是两条五年暗线在 2025 的必然汇合:
暗线 A|自监督:把"无 label 学表征"做成可复用的工业品 / 世界模型
MoCo ──► SimSiam/BYOL ──► MAE ──► DINOv2 ──► V-JEPA2
'19 '20 '21 '23 '25
对比 stop-grad / 掩码 通用视觉 预测式
学习 无需负样本 重建 特征 world model
│
frozen 特征 / world model 随手可取
│
├───► 2025
暗线 B|生成:扩散模型本身就是一个自监督模型 │ 汇合
diffusion 训练目标 = 去噪 = 无 label 自监督 │
→ 它天生就在学表征 ─────────────────────────────┘
▼
把"现成的好表征 / world model"接进"天生学表征的生成模型"
VA-VAE / REPA / RAE(训练时注入) · V-JEPA2(推理时注入)
换句话说:当"现成的好表征"(DINOv2 / MAE 的 frozen 特征)和"天生就在学表征的生成模型"(扩散)同时摆上桌,把它们对齐几乎是必然被走通的一步。这条汇合背后,其实藏着一条更完整的因果链。
💡 这篇 blog 想讲清楚的一条因果链
这篇 blog 不打算逐篇罗列"今年又有谁对齐了谁",而是想沿着四条递进的线,把"diffusion 和表征 / 流形到底是什么关系"讲成一个连贯的故事。后文统一用 §1–§6 编号,四条线对应 §1–§4,§5 把它们接到语言侧的 continuous DLM,§6 收束:
- §1 — 扩散模型 = 天然的 SSL(objective 视角):从训练目标出发,说明 denoising 本身就是一个无 label 的自监督任务,diffusion 训练免费附带表征学习;并把它和 SSL 的两大流派(contrastive / non-contrastive)、以及 Consistency Models 的结构对应起来。
- §2 — diffusion 自己学出的表征长什么样、何时学坏:既然是 SSL,它学到的表征就值得被打开看。Qing Qu 组的两篇可解释性工作 [1][2] 给出"什么是好表征、什么时候塌掉"的判据。
- §3 — 与其自己慢慢学,不如外部注入现成 SSL 表征:VA-VAE [3] / REPA [4] / RAE [5] / V-JEPA2 [6] 分别在 VAE 层、latent 层、inference 层注入表征。
- §4 — 绕开表征,直接用数据自身的流形结构:一项 VAE-manifold + 浅层 MoE 的工作 [7]、Kaiming 的 x-prediction / JiT [8]、以及 inference-time 的 predict–perturb [9]。
四条线背后是同一个主题:让生成模型少做无用功,多用数据本身的结构先验——无论这个先验是以"表征"还是"流形"的形式出现。我们从最底层的训练目标讲起。
1 · 扩散模型 = 天然的 SSL(Objective Function 视角)
要理解"diffusion 为什么天生在学表征",最干净的入口不是去看它的网络架构,而是去看它的训练目标。一个模型在学什么,由 loss 决定,不由层数决定。我们先把扩散模型的 objective 写出来,再把它和自监督学习(self-supervised learning, SSL)的 objective 摆在一起对照——你会发现它们其实是同一个家族。
1.1 扩散训练的本质:预测"被破坏数据的干净版本"
扩散模型(以及它的连续时间表亲 flow matching / rectified flow)的训练,可以统一描述成一句话:给定一个被噪声破坏的样本,去预测它干净的样子(或者等价地,预测破坏它的那个噪声 / 速度场)。注意这里完全没有用到任何 label——你需要的只是干净数据 \(x_0\),噪声是自己加的,"答案"也是 \(x_0\) 自己。这正是自监督的定义:监督信号来自数据本身。
具体地,扩散的前向过程把干净数据 \(x_0\) 逐步加噪,得到 \(x_t = \alpha_t\, x_0 + \sigma_t\,\epsilon,\ \epsilon \sim \mathcal{N}(0, I)\)(\(\alpha_t, \sigma_t\) 是 noise schedule 决定的系数,\(t\in[0,1]\) 是噪声强度)。模型 \(s_\theta\) 要学的,是从含噪的 \(x_t\) 中"恢复信息"。根据"恢复什么"的不同,主流有三种等价的参数化(parameterization):
① ε-prediction / Denoising Score Matching
让网络预测当初加进去的噪声 \(\epsilon\):
$$\mathcal{L}_{\epsilon} = \mathbb{E}_{x_0,\,\epsilon,\,t}\Big[\big\| \epsilon_\theta(x_t, t) - \epsilon \big\|^2\Big].$$这与经典的 denoising score matching(DSM)紧密相关,但要区分两个 score:给定 \(x_0\) 的条件 score 满足 \(\nabla_{x_t}\log q(x_t\mid x_0) = -\,\epsilon/\sigma_t\);而训练收敛后 \(\epsilon_\theta(x_t,t)\) 学到的是后验均值 \(\mathbb{E}[\epsilon\mid x_t]\),对应边际 score \(\nabla_{x_t}\log p_t(x_t) = -\,\mathbb{E}[\epsilon\mid x_t]/\sigma_t\)(Tweedie 公式)——两者差一个对 \(x_0\) 的后验期望。核心是:"去噪"和"估计数据分布的对数梯度(score)"紧密相通——这是 diffusion 与 score-based model / 能量模型之间的桥。
② x-prediction
让网络直接预测干净数据 \(x_0\):
$$\mathcal{L}_{x} = \mathbb{E}_{x_0,\,\epsilon,\,t}\Big[\big\| x_\theta(x_t, t) - x_0 \big\|^2\Big].$$形式上这就是一个denoising autoencoder:输入被噪声破坏的 \(x_t\),输出尽量还原 \(x_0\)。\(x\)-pred 和 \(\epsilon\)-pred 通过 \(x_t = \alpha_t x_0 + \sigma_t \epsilon\) 可以互相换算,但数值行为不同——后面 §4 会讲到,当数据落在低维流形上时,直接预测低维的 \(x_0\) 比预测高维的 \(\epsilon\) 更稳、更直接(这正是 JiT [8] 与 ELF 选择 x-pred 的理由)。
③ v-prediction(velocity)
第三种是 v-prediction(Salimans & Ho):在 VP / DDPM 参数化下,预测一个把 \(x_0\) 和 \(\epsilon\) 混合起来的"速度"量 \(v_t \triangleq \alpha_t\,\epsilon - \sigma_t\,x_0\):
$$\mathcal{L}_{v} = \mathbb{E}_{x_0,\,\epsilon,\,t}\Big[\big\| v_\theta(x_t, t) - v_t \big\|^2\Big].$$v-pred 的好处是在不同噪声强度 \(t\) 下信号尺度更均衡(这也是它在 distillation / few-step 采样里流行的原因)。在同一条 noise schedule 下,\(\epsilon\)-/\(x\)-/\(v\)-pred 三者都可由 \(x_t = \alpha_t x_0 + \sigma_t\epsilon\) 线性互换、学的是同一个映射,只是投影方向不同。(另一个相关但不同的框架是 rectified flow / flow matching:它用线性插值 \(z_t=(1-t)\epsilon+t\,x_0\)、速度场为常量 \(\frac{\mathrm{d}z_t}{\mathrm{d}t}=x_0-\epsilon\)。v-pred 与 rectified-flow velocity 都属"预测 \(x_0\) 与 \(\epsilon\) 的某种线性组合"的思路,但 schedule 与 velocity 定义不同,不要混为一谈——ELF 用的正是 rectified-flow 这一支。)
不管选哪种参数化,故事的内核都一样:制造一个"破坏 → 恢复"的自监督任务,强迫网络从被污染的输入里把信息抽回来。而"为了从含噪输入恢复干净数据,你必须理解数据的内在结构"——这正是表征学习的全部动机。一个能在各种噪声水平下把猫的图片去噪干净的网络,它的中间层几乎必然编码"什么是猫"的语义。表征与其说是 diffusion 的副产品,不如说是去噪任务能被解决的前提。
🎯 takeaway(1.1)
denoising 本身就是一个自监督任务。扩散模型的训练目标——无论写成 DSM / x-pred / v-pred——都只用到数据自身、不用任何 label,与 MAE 的"掩码—重建"、denoising autoencoder 的"加噪—还原"是同一种自监督范式。所以 diffusion 训练免费附带了表征学习:你为了把图去干净,顺手就把数据的语义结构学进了中间层。这是 §2「打开 diffusion 中间层当表征用」之所以可能的根本原因。
1.2 SSL 的两大流派:contrastive 与 non-contrastive
既然 diffusion 是 SSL,就值得把它放回 SSL 这个大家族里定位一下。无监督 / 自监督表征学习这几年大致分成两条主线,它们的差别恰好体现在 objective 上。
(a) Contrastive(对比式)——以 InfoNCE 为代表。核心思想是"拉近正样本、推开负样本":对同一张图做两次不同的数据增广得到 \(q\)(query)和 \(k^+\)(正 key),再从其它图采一批负 key \(\{k^-_j\}\),让模型学到的表征满足"正对相似、负对不相似"。MoCo / SimCLR 用的 InfoNCE loss:
$$\mathcal{L}_{\text{InfoNCE}} = -\,\mathbb{E}\left[\log \frac{\exp\!\big(\langle q,\,k^+\rangle/\tau\big)}{\exp\!\big(\langle q,\,k^+\rangle/\tau\big) + \sum_{j}\exp\!\big(\langle q,\,k^-_j\rangle/\tau\big)}\right],$$其中 \(\tau\) 是温度系数。InfoNCE 本质是一个"在一堆负样本里把正样本认出来"的分类问题,它需要大量负样本才能学到有判别力的表征——MoCo 的关键贡献之一就是用一个 momentum-updated 队列来廉价地维护一个大负样本池。
(b) Non-contrastive(非对比式)——以 SimSiam / BYOL 为代表。这条线的惊人之处在于:它根本不用负样本。BYOL 用一个 online network 和一个 EMA(指数滑动平均)更新的 target network,让 online 去预测 target 对同一张图另一增广视图的表征;SimSiam 更激进地证明,连 EMA 都可以不要,只要一个 stop-gradient 就够了。SimSiam 的 objective(对称化前)大致是:
$$\mathcal{L}_{\text{SimSiam}} = -\,\Big\langle\, p\big(f(x_1)\big),\ \operatorname{sg}\!\big[f(x_2)\big]\,\Big\rangle,$$其中 \(f\) 是共享的 encoder,\(p\) 是一个 predictor MLP(只加在一边),\(x_1, x_2\) 是同图两次增广,\(\operatorname{sg}[\cdot]\) 是 stop-gradient(梯度不回传到那一支)。直觉上,"两边都想互相靠近、又没有负样本"应该会塌缩到平凡解(所有输入映到同一个常向量,loss=0);SimSiam 揭示了非对称结构(predictor + stop-gradient)正是阻止这种 collapse 的关键——它隐式地扮演了一个 EM 式交替优化 / 在线聚类的角色,让一支当"会动的学生"、另一支当"被冻住的目标"。

💡 diffusion 落在 SSL 谱系的哪里?
把三者放到一张表上对照,它们共享"监督信号来自数据本身"这个根,但制造监督的方式不同:
| 流派 | 代表 | 怎么造监督信号 | 怎么防塌缩 |
|---|---|---|---|
| Contrastive | MoCo / SimCLR (InfoNCE) | 正对增广 vs 大量负样本 | 负样本天然撑开表征空间 |
| Non-contrastive | SimSiam / BYOL | 同图两视图互相预测 | predictor + stop-gradient(非对称) |
| Denoising(含 diffusion) | MAE / DAE / Diffusion | 破坏数据 → 恢复干净版本 | 重建目标本身有信息量,不会塌到常数 |
diffusion 属于第三类denoising-based SSL:它和 MAE 是近亲——MAE 用"掩码"破坏、diffusion 用"加噪"破坏,但都靠"恢复被破坏的数据"来逼出表征。下一小节会看到,Consistency Models 这个变体,把 diffusion 又拉回了第二类(non-contrastive)的结构,从而在两条线之间架了一座桥。
1.3 Consistency Models:与 BYOL / SimSiam 结构相通的扩散变体
Consistency Models(CM,及其训练版 Consistency Training, CT)原本是为了一步 / 少步生成提出的:标准 diffusion 要沿 PF-ODE(probability-flow ODE)轨迹积分几十上百步才能从噪声走到数据,CM 想训一个函数 \(f_\theta\),让它把同一条轨迹上的任意点都直接映射到这条轨迹的终点(干净数据)。一旦学成,单次前向就能从纯噪声跳到样本。它的训练目标是一个自一致性(self-consistency)约束:相邻两个时间点 \(t_{n+1} > t_n\) 上的 \(f_\theta\) 输出应当一致。
关键在于 CT loss 长成这个样子(写成最常见的离散化形式):
$$\mathcal{L}_{\text{CT}} = \mathbb{E}\Big[\, d\big(\, f_\theta(x_{t_{n+1}},\, t_{n+1}),\ \operatorname{sg}\!\big[\, f_{\theta^-}(x_{t_n},\, t_n)\,\big]\,\big)\,\Big],$$其中 \(d(\cdot,\cdot)\) 是距离度量(如 \(\ell_2\) 或 LPIPS),\(\theta^-\) 是 \(\theta\) 的 EMA 副本(target network),\(\operatorname{sg}[\cdot]\) 是 stop-gradient。把这个式子和上一节 BYOL / SimSiam 的 objective 并排看——结构几乎一模一样:
BYOL / SimSiam(表征自监督) Consistency Training(生成 / 去噪)
───────────────────────── ──────────────────────────────
x(一张图) x_0(一条 PF-ODE 轨迹上的干净数据)
╱ ╲ 两次增广 ╱ ╲ 加到两个相邻噪声水平
x_1 x_2 x_{t_{n+1}} x_{t_n} (t_{n+1} > t_n)
│ │ │ │
f_θ │ │ f_θ (shared / EMA) f_θ │ │ f_{θ⁻} (EMA target)
▼ ▼ ▼ ▼
p(·) [ stop-grad ] f_θ 输出 [ stop-grad ]
学生支 冻结的目标支 学生支 冻结的目标支
╲ ╱ ╲ ╱
── 拉近 ── ── 拉近(自一致性)──
共同骨架: 「会更新的学生」 ⟷ 「被 stop-gradient 冻住的目标」
student = f_θ(更噪的点 x_{t_{n+1}}) (t_{n+1} 噪声更大)
target = sg[ f_{θ⁻}(更干净的点 x_{t_n}) ] ← EMA + 停梯度, t_n 更接近数据
这个对应不止是表面类比,而是结构上的高度相似:BYOL / SimSiam 用 "(online student, EMA/stop-grad target)" 防止表征塌缩并学出语义结构;CT 用同样的 "(student at \(t_{n+1}\), stop-grad EMA target at \(t_n\))" 把整条轨迹钉到同一个终点。两者都没有负样本,都靠 stop-gradient 的非对称性稳住训练。从这个视角看,Consistency Training 可以理解为一种被 PF-ODE 轨迹"组织"起来的 non-contrastive SSL——只不过它的"两个视图"不是来自随机增广,而是来自同一条去噪轨迹上的两个噪声水平。(需说明:CM 的设计初衷是 PF-ODE 轨迹一致性与少步生成,"它也是一种 SSL"是一个解读视角,而非它的定义。)
💡 为什么"input image → output image + 轨迹一致性 = 隐式学数据流形"
这里要换一个视角:从 JiT [8] 那种"把生成模型当 denoiser"的角度看,CM 的输入是含噪图、输出还是图(image → image),而它强加的约束是——同一条 PF-ODE 轨迹上的所有点,都要被映射到同一个终点 \(x_0\)。
PF-ODE 的终点 \(x_0\) 落在真实数据流形上;而轨迹上那些含噪点 \(x_t\) 是从流形"飘出去"的、偏离流形的点。于是 CM 学的那个映射 \(f_\theta\),可以理解为一个近似把噪声空间投影回数据流形的算子(approximate projection onto the data manifold):
f_θ : 偏离流形的含噪点 x_t ⟼ 流形上的干净点 x_0
"自一致性"约束正是在要求这个投影沿整条轨迹一致——也就是说,轨迹上不同高度的点必须落到流形上的同一个点。要满足这个约束,网络就需要学到数据流形的大致形状:它得知道"哪些方向是离开流形的噪声、应该被压回去,哪些方向是流形内部的语义变化、应该保留"。这就是为什么"image→image + 轨迹一致性"对应于隐式地学数据流形的投影结构,也顺带降低了单步 / 少步生成的训练难度——因为投影到流形比"凭空合成一张图"是一个结构更明确、更受约束的任务。这条"利用数据流形"的暗线,会在 §4 被正面展开。
🎯 takeaway(§1)
- denoising 本身就是 SSL:扩散的训练目标(DSM / x-pred / v-pred)只用数据自身、不用 label,与 MAE / DAE 同属 denoising-based 自监督。diffusion 训练免费附带表征学习。
- diffusion 在 SSL 谱系里有明确位置:contrastive(InfoNCE,靠负样本)/ non-contrastive(SimSiam·BYOL,靠 predictor + stop-gradient)/ denoising(MAE·diffusion,靠重建)三足鼎立,diffusion 属第三类,且与 MAE 是近亲。
- Consistency Models 把 diffusion 拉回 non-contrastive 结构:CT 的 "(student, stop-grad EMA target)" 与 BYOL / SimSiam 结构相通;并且"image→image + 轨迹一致性"可理解为隐式学习近似把噪声空间投影回数据流形。
- 这一切都指向 §2 的问题:既然 diffusion 天生在学表征,那它实际学出来的表征长什么样、什么时候会学坏?
2 · diffusion 自己的 SSL 表征长什么样,又何时学坏
§1 我们论证了:denoising 本身是一种自监督任务,所以 diffusion 在学会生成的同时,顺手就把表征学了。这听上去很美好——免费的午餐。但凡是免费的东西,往往都有隐藏的代价。这一节我们要把"diffusion 表征"这件事拆开看清楚:它藏在哪一层、哪个噪声尺度;它为什么有时很好、有时很糟;以及最关键的——表征的好坏,居然和模型泛化还是记忆是同一件事的两面。我们会跟着 Qing Qu 组的两篇可解释性工作 [1][2],把这个故事讲清楚。
2.1 中间层为什么能当表征:噪声尺度就是语义粒度的旋钮
回忆 diffusion 的前向过程:从干净数据 \(x_0\) 出发,逐步注入噪声,得到一族被破坏的样本
$$ x_t = \alpha_t\, x_0 + \sigma_t\, \epsilon, \qquad \epsilon \sim \mathcal{N}(0, I), $$其中信噪比 \(\mathrm{SNR}(t) = \alpha_t^2 / \sigma_t^2\) 随 \(t\) 单调下降:\(t\to 0\) 几乎是干净图像,\(t\to T\) 几乎是纯噪声。网络 \(f_\theta(x_t, t)\)(无论它预测的是 \(\epsilon\)、\(x_0\) 还是 score \(\nabla_{x_t}\log p_t\))要在每一个噪声尺度上都把被破坏的输入还原回干净流形。这意味着同一个网络被迫在一条连续的"难度谱"上学习去噪。
关键的直觉在于:在不同噪声尺度下完成去噪所需的信息是不一样的,因此网络在不同 \(t\) 下被迫编码不同粒度的语义。
高噪声 t→T ┃ 输入≈纯噪声,几乎看不见原图
(low SNR) ┃ 要还原,只能靠"这类数据长什么样"的全局先验
┃ → 网络编码:粗语义 / 类别 / 全局布局 / 大色块
┃ (coarse, global, semantic)
┃
中等噪声 t≈t* ┃ 既有部分结构残留,又需大量先验补全
(mid SNR) ┃ → 全局语义 + 局部结构都要用上
┃ ★ 经验上这里表征最有用(见 2.2 单峰)
┃
低噪声 t→0 ┃ 输入≈干净图,只剩高频细节待补
(high SNR) ┃ → 网络编码:纹理 / 边缘 / 像素级细节
┃ (fine, local, low-level)
这正是为什么 diffusion 的中间层激活能直接拿去做下游分类、分割等任务,且效果不错:高噪声分支学到的全局语义,恰好是判别任务想要的东西;而扫一遍不同的 \(t\) 和不同的层,等于得到了一组多粒度、多尺度的特征金字塔。换句话说,diffusion 不是只学了"怎么画",它在学"怎么画"的过程中,被迫把数据的层次化结构内化进了网络的中间表示里。这也是 2025 年那一大波"把 diffusion 中间层和 SSL 对齐"工作(§3 会展开)的物理基础——既然里面已经有表征,那就有得对齐、有得借用。
2.2 表征质量沿扩散时间的单峰动力学,以及它何时塌掉
既然不同 \(t\) 编码不同粒度,一个自然的问题是:哪个 \(t\) 的表征最有用? Qing Qu 组的工作 [1] 通过低维建模来理解 diffusion 的表征动力学,给出了一个干净而漂亮的现象——表征质量随扩散时间 \(t\) 呈单峰(unimodal)曲线。
定性地说:如果我们沿着 \(t\) 把中间表征拿去测一个下游可用性指标(例如线性可分性 / 下游探针性能),会得到一条先升后降的钟形曲线——
$$ \text{(表征质量)}\;\; Q(t) \;\;\text{随 } t \text{ 先升后降,在某个中间尺度 } t^* \text{ 达到峰值。} $$- 太低噪声(\(t\to 0\)):输入几乎就是原图,网络没有被逼着抽象,表征里塞满了低层细节,全局语义反而稀薄——下游可用性不高。
- 太高噪声(\(t\to T\)):输入几乎是纯噪声,可还原的信息太少,表征退化为对边缘分布的笼统先验,丢掉了样本特异的结构——可用性也不高。
- 中间尺度(\(t^*\)):恰好"既有残留结构可抓、又被逼着调用全局先验",全局语义与局部结构在此交汇,表征最有用。这就是单峰的峰。
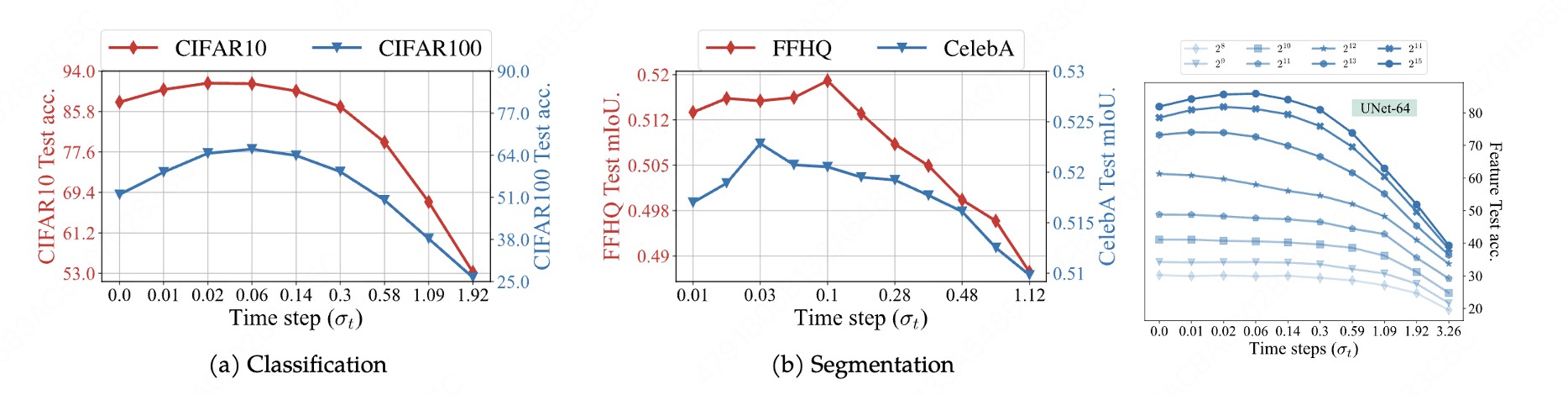
真正深刻的地方在于第二句话:这个单峰结构是否存在,是模型是否泛化的"指示灯"。 [1] 观察到,当模型不具备泛化性、退化成对训练集的局部记忆时,原本随尺度连续演化的单峰动力学会逐渐瓦解。直觉上不难理解——
泛化的模型: 学到的是"数据流形"的尺度组织 高 t → 抓流形的全局形状(语义) 低 t → 抓流形的局部细节(纹理) ⇒ 沿 t 形成连续、由粗到细的语义层次 ⇒ 表征质量 Q(t) 单峰,峰在 t* 记忆的模型: 学到的是"训练样本的查找表" 无论 t 多大,目标都是检索回某个见过的 x0 ⇒ 没有"按尺度组织语义"这件事可言 ⇒ Q(t) 单峰结构 → 塌掉 / 变平 / 畸形
泛化的模型把噪声尺度当成"放大数据流形的旋钮",于是表征沿 \(t\) 自然铺开成由粗到细的层次,呈现单峰;记忆的模型则把每个噪声样本都当成"该回到哪张见过的图"的检索问题,尺度不再承载语义组织,单峰也就无从谈起。于是"有没有单峰"成了一个可观测、可解释的泛化探针——你不需要知道测试集,只要看表征沿 \(t\) 的动力学是否健康,就能判断模型是在理解数据还是在背答案。
2.3 表征的谱结构:balanced 还是 spiky,就是泛化还是记忆
如果说 2.2 是沿"时间轴 \(t\)"看表征,那么 [2] 提供了一个互补的、沿"特征空间方向"看表征的视角。其核心论点是:diffusion 模型的泛化,伴随着一个 balanced 的表征空间出现;训练不好的模型,其表征是 spiky 的。
这里的"谱"指的是表征所张成的特征空间的方向分布。我们可以借用协方差谱来获得直觉:把模型在数据上诱导的表征收集起来,看它的方向能量是均匀铺开还是挤在少数方向上。
$$ \Sigma \;=\; \mathbb{E}\big[(h-\bar h)(h-\bar h)^\top\big], \qquad \text{特征值谱}\;\; \lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_d \ge 0 . $$- Spiky(尖刺型,训坏 / 记忆):少数几个 \(\lambda_i\) 极大、其余迅速衰减到接近 0。能量塌缩到极低维的几个方向上——这正是过拟合 / 记忆的几何签名:模型只沿着"复现训练样本"所需的那几个方向用力,没有去覆盖数据流形的其余结构。这也呼应了表征学习里 contrastive / non-contrastive 方法竭力避免的维度坍缩(dimensional collapse)。
- Balanced(均衡型,训好 / 泛化):能量在更多方向上较为均匀地铺开,谱"平"。模型充分挖掘了数据分布的多种变化因子,表征覆盖了数据真实流形的多个方向,因而泛化好。
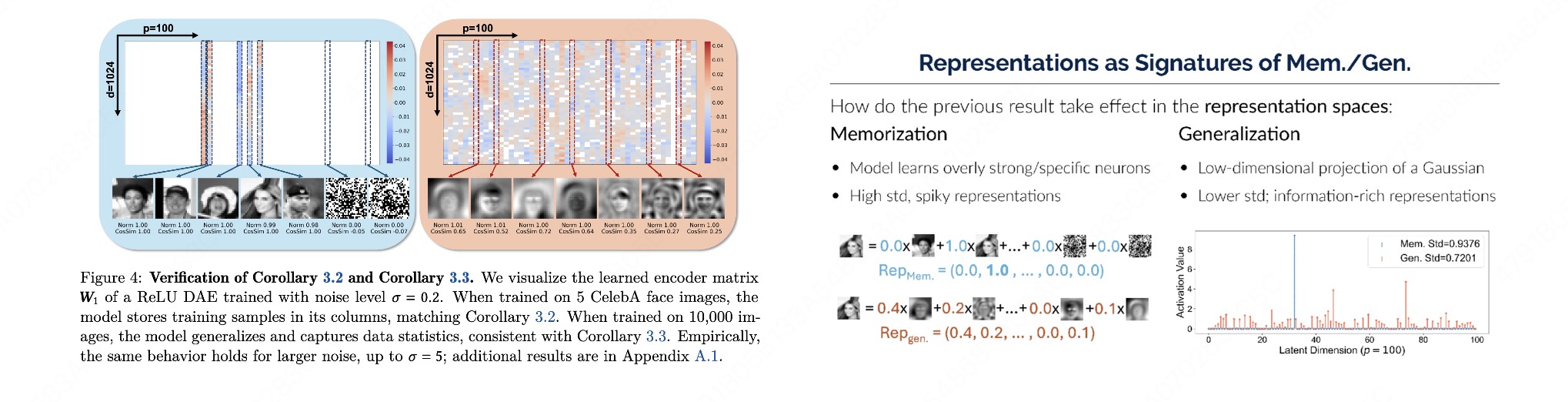
2.4 把两条线缝起来:表征好坏、泛化、学到流形三者高度相关
到这里,[1] 的"单峰动力学"和 [2] 的"balanced 谱"其实在讲同一件事,只是从两个不同的切面观察:
┌──────────────────────────┐
沿时间轴 t 看 ───────▶ │ 单峰动力学存在 [1] │
(扩散尺度方向) │ Q(t) 先升后降,峰在 t* │
└────────────┬─────────────┘
│ 同一件事
┌────────────┴─────────────┐
沿特征方向看 ─────────▶ │ balanced 表征谱 [2] │
(协方差谱方向) │ 能量在多方向均衡铺开 │
└────────────┬─────────────┘
▼
┌─────────────────────────────────────┐
│ 本质:模型学到了数据的【真实流形】 │
│ 而不是【记忆个别训练样本】 │
│ ⇒ 泛化 (generalization) │
└─────────────────────────────────────┘
反面:单峰塌掉 ∧ 谱 spiky ⇒ 记忆 / 过拟合 ⇒ 不泛化
两个现象共同的底层变量,就是 manifold hypothesis 意义下的那句话——泛化 = 学到了数据的真实低维流形,记忆 = 只记住了流形上散落的几个样本点。学到流形的模型,会把噪声尺度组织成由粗到细的语义层次(→ 单峰),并在特征空间里沿流形的多个方向均衡铺开能量(→ balanced 谱);只记住样本的模型,既无尺度层次(单峰塌掉),也只用得到指向那几个记忆点的少数方向(spiky 谱)。两个看似无关的可解释性现象,原来是同一枚硬币的正反面。
- 表征不是免费午餐:§1 说"denoising 顺手就学了表征"是对的,但表征的质量完全依赖训练是否健康、模型是否泛化。训坏 / 记忆时,表征会真的"学坏"。
- 表征质量可作泛化的可解释探针:在这些工作的设定下,表征沿 \(t\) 是否单峰 [1]、谱是否 balanced [2],是判断模型在"理解数据"还是"背答案"的可靠相关信号(不必只依赖测试集)。这把抽象的"泛化"部分地变成了可观测的几何量。
- 核心张力是流形 vs. 记忆:好表征、泛化、学到真实流形而非记忆样本,三者紧密相关。这条主线既是本节的落点,也为后两节埋下伏笔——既然好表征如此依赖泛化、又这么难自发拿稳,那么(§3)干脆从外部注入现成的 SSL 好表征,或者(§4)绕开表征、直接利用数据流形结构,就成了两条顺理成章的出路。
3 · 借外部 SSL 表征:三层注入与"站在巨人肩上"
§2 留下一个尴尬的现实:扩散模型确实自带表征学习,但这份表征是否"长得好",强依赖于训练是否充分、是否真的泛化到了数据流形上。换句话说,"自发学好表征"这件事,难把握、不稳定、还贵——你得把整个生成模型训到接近收敛、训到泛化,才能顺带收获一套 balanced 的中间层表征。这就引出一个很自然的反问:
这个"借表征"的思路在 2025 年集中爆发,并且形成了一条从底层到推理、贯穿整个生成 pipeline 的注入谱。我们可以按"注入发生在哪一层"把它们排成三档:
frozen SSL encoder (MAE / DINOv2 / V-JEPA2)
│ 借来的"语义坐标系"
┌─────────────────────┼─────────────────────┐
▼ ▼ ▼
(a) VAE 层 (b) latent / 中间层 (c) inference 层
VA-VAE [3] REPA [4] / RAE [5] V-JEPA2 [6]
───────── ────────────────── ──────────────
对齐 VAE latent REPA: DiT 中间层加 生成时把样本拉向
与 SSL 特征 alignment loss 拉向 SSL SSL 流形 = "物理裁判"
→ latent 富语义 RAE: 干脆在 SSL 潜空间 → 真实感 / 物理合理性
→ 解重建-生成两难 上训 decoder + DiT
│ │ │
训练前 / 底层 训练中 / 表征层 训练后 / 推理时
└─────────────────────┴─────────────────────┘
共同点:被借的 encoder 始终 frozen,
生成模型只学"如何对齐 / 如何在这个空间里生成"
注意这三档不是互斥的竞品,而是同一思想在不同位置的落点。下面逐一拆开机制。
3.1 VAE 层注入:VA-VAE 让 latent 既能重建、又有语义
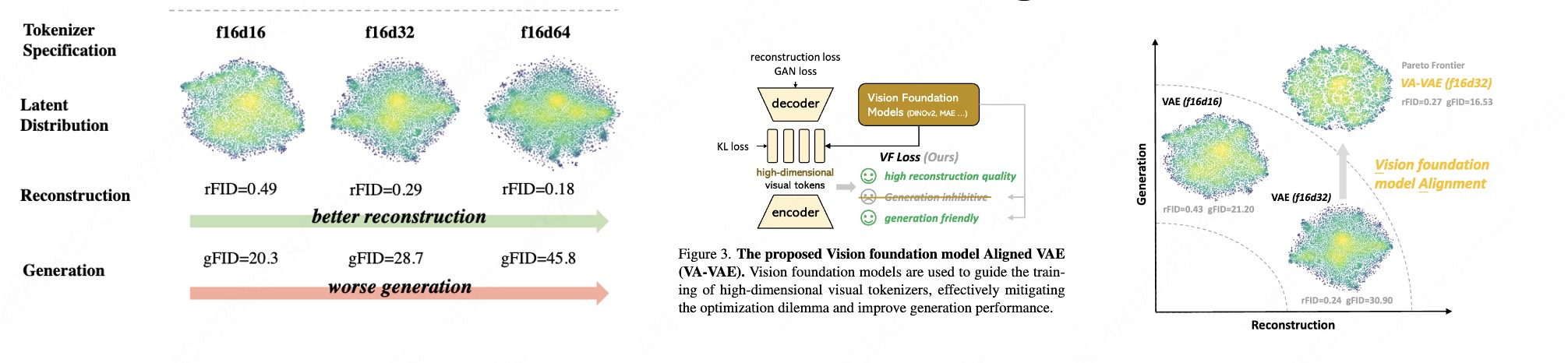
现代主流是 latent diffusion:先用一个 VAE 把图像压到低维 latent \(z\),再在 \(z\) 空间上跑 diffusion。问题出在这个 VAE 的训练目标上。VAE 通常只优化"重建"——它只在乎 \(z\) 能不能把图像还原回去:
$$\mathcal{L}_{\text{VAE}} \;=\; \underbrace{\big\|\, x - \mathrm{Dec}(z)\,\big\|^2}_{\text{重建}} \;+\; \beta\,\underbrace{\mathrm{KL}\big(q(z\mid x)\,\|\,p(z)\big)}_{\text{正则}},\qquad z = \mathrm{Enc}(x).$$这里有一个被反复观察到的优化两难(optimization dilemma):要重建得好,latent 维度往往要开得很大、信息要塞得很满;但维度一大、信息一密,这个 latent 空间就变得"语义上很难看"——相邻语义的点在 latent 里乱成一团,重建质量上去了,但下游 diffusion 反而更难学、更难训出好生成。直白说就是:VAE 重建好,不代表它的 latent 有语义。
VA-VAE [3] 的解法非常对症:在原本只管重建的 VAE 上,额外加一项 vision-foundation alignment loss,把 VAE 的 latent \(z\) 往 frozen 的 SSL 特征(MAE / DINOv2)上对齐:
$$\mathcal{L}_{\text{VA-VAE}} \;=\; \mathcal{L}_{\text{VAE}} \;+\; \lambda\,\underbrace{\mathcal{L}_{\text{align}}\Big(\,\mathrm{proj}(z),\;\; f_{\text{SSL}}^{\text{frozen}}(x)\,\Big)}_{\text{对齐到冻结 SSL 语义}},$$其中 \(f_{\text{SSL}}^{\text{frozen}}\) 是冻结不动的 DINOv2/MAE,\(\mathrm{proj}\) 是一个轻量投影头,\(\mathcal{L}_{\text{align}}\) 通常是逐元素 + 余弦相似度的混合。这一项相当于给 VAE 的 latent 装上一套来自 SSL 的"语义坐标系":latent 既要能重建(满足 \(\mathcal{L}_{\text{VAE}}\)),又被强迫在结构上和"已经学好语义的 DINOv2"保持一致。结果就是 latent 同时具备高保真重建与良好语义结构,下游 diffusion 在这个空间里训得更快、生成更好——优化两难被打破。
3.2 latent / 中间层注入:REPA 加速训练,RAE 直接借空间
第二档把注入点从 VAE 挪到 diffusion 主干(DiT)自己。这里有两个代表,强度截然不同:一个是"温和地拉一把"(REPA),一个是"干脆全盘借用"(RAE)。
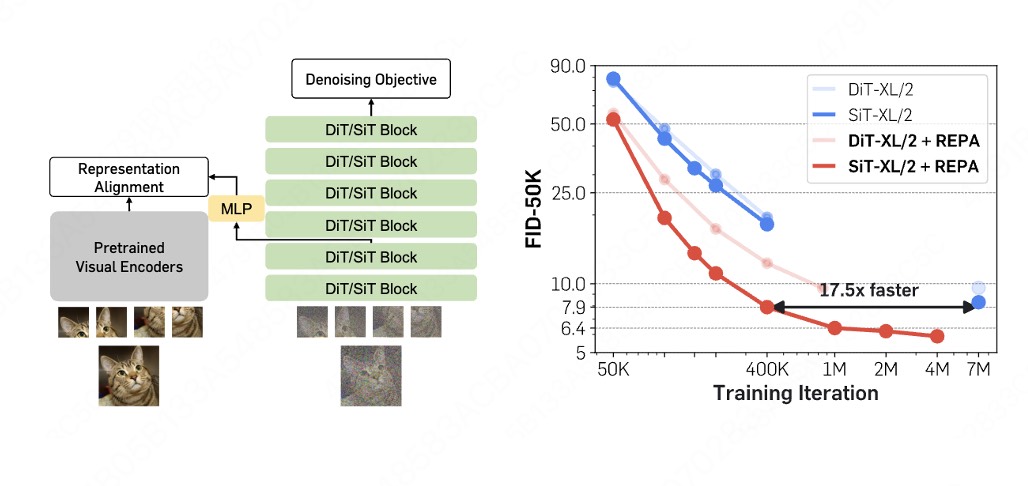
REPA:在 DiT 中间层加一条 alignment loss
REPA [4](Saining Xie 组,标题就叫 "Diffusion Transformers is Easier Than You Think")的观察是:DiT 在训练过程中其实正在缓慢地、自己重新发明一套和 DINOv2 类似的表征——但它学得很慢,因为它得一边学生成、一边顺带把表征摸索出来(这正是 §1/§2 说的"diffusion 自带 SSL,但表征要靠训练慢慢长出来")。既然如此,为什么不直接把答案告诉它?
REPA 的做法极简:取 DiT 某个中间层的 hidden state \(h_\ell(x_t)\),过一个小 MLP \(h_\phi\),强迫它对齐到 frozen DINOv2 在干净图像 \(x\) 上的特征 \(f_{\text{SSL}}(x)\)。总目标就是在原本的 diffusion loss 上加一项:
$$\mathcal{L} \;=\; \underbrace{\mathcal{L}_{\text{diffusion}}}_{\text{denoising / 生成}} \;+\; \lambda\,\underbrace{\mathbb{E}\Big[\, -\,\mathrm{sim}\big(\,h_\phi(h_\ell(x_t)),\; f_{\text{SSL}}(x)\,\big)\,\Big]}_{\text{REPA:中间层拉向冻结 SSL}},$$其中 \(\mathrm{sim}\) 一般是余弦相似度,\(x_t\) 是加噪输入、\(x\) 是干净图像。注意这一项只在训练时存在:它像一根"语义脚手架",把 DiT 的中间层快速拽到一个好表征上,省去了模型自己慢慢摸索的过程。代价几乎为零(一个小 MLP + 一个 frozen encoder 的前向),但 DiT 的训练收敛大幅加速——这正是标题想说的"比你想的简单"。
RAE:把 SSL 潜空间直接当作生成空间(Diffusion Transformers with Representation Autoencoders)
RAE [5] 把"借"做到了极致。REPA 还保留了 DiT 自己的空间、只是把中间层往 SSL 拉;RAE 则连空间都不要自己的了——它直接把 frozen SSL encoder(DINOv2 这类)的输出潜空间,当成 diffusion 要生成的目标空间。整个 pipeline 变成:
图像 x ──► [ frozen SSL encoder ] ──► 语义潜表征 z = f_SSL(x)
(完全不训) │
▼
[ diffusion / DiT 在 z 空间建模分布 ]
│ (这部分仍需训练)
▼ 生成出 ẑ
[ decoder ] ──► 图像 x̂
(与 encoder 配成 representation
autoencoder, 需训练)
也就是说:encoder 是借来的、冻结的;需要训练的有两部分——(a) 一个把潜表征解码回像素的 decoder(与 frozen encoder 一起构成 "representation autoencoder"),和 (b) 在这个 representation 潜空间上建模分布的 diffusion / DiT 本身。关键在于:因为这个潜空间本来就是 SSL 精心学好的、语义高度结构化的,diffusion 在上面建模异常省力、收敛更快——省掉的是"从头学语义"这件事,而不是"不用训 diffusion"。

$$\underbrace{\text{RAE}}_{\text{图像}}:\;\; \text{frozen DINOv2} \;+\; \text{轻量 decoder} \qquad\Longleftrightarrow\qquad \underbrace{\text{ELF}}_{\text{语言}}:\;\; \text{frozen T5} \;+\; \text{共享 decoder}$$
两者都在说同一句话:语义 encoder 不用自己学,借现成的、冻结它;生成模型只需要学"如何在这个借来的空间里生成"。图像扩散的"借 SSL 表征"和语言 DLM 的"借 T5 表征"是同一个 idea 在两个模态上的实例。详见 §5 与 continuous DLM blog 中关于 ELF frozen encoder + shared decoder 的讨论。
3.3 inference 层注入:用 SSL 流形当生成时的"真实性裁判"
前两档都在训练阶段注入 SSL。第三档更激进:训练完全不动,只在采样(inference)时借 SSL 表征来"纠偏"。它的逻辑链是这样的:
- SSL 模型(尤其像 V-JEPA 这类 predictive world model)是在海量真实数据上训出来的,它的表征空间里"什么是真实的、物理上合理的"被刻画得很到位;
- 而生成模型采出来的样本,可能在像素上看着还行,但在"物理是否说得通"上经常翻车(视频尤其明显:物体穿模、运动不连贯、违反重力等);
- 那就把生成样本和真实样本都投影到 SSL 的表征流形上,用"在这个流形上是否落在真实样本附近"作为一个guidance 信号,在采样时把生成样本往真实流形上推。
V-JEPA2 [6] 正是把这套用在视频生成的物理合理性上:它把 V-JEPA2(一个在海量真实视频上训练的 predictive world model)当作一个 reward / 真实性裁判——在采样时对多条候选 denoising 轨迹评分,favor 那些在 V-JEPA2 表征空间里更接近"真实视频"的轨迹,从而把生成结果往物理上合理的方向 steer。直觉上,V-JEPA2 充当了一个"物理 / 真实性裁判":它不在乎你像素上画得多漂亮,只看你在它学到的世界模型表征里是否落在"真实视频"该在的位置。这把对齐从训练时挪到了推理时——是一个 training-free 的注入方式,可直接套在已有视频生成模型外面。(具体是 inference-time 的 search / steering,而非对某个流形距离做梯度下降;这里不展开其精确算法。)
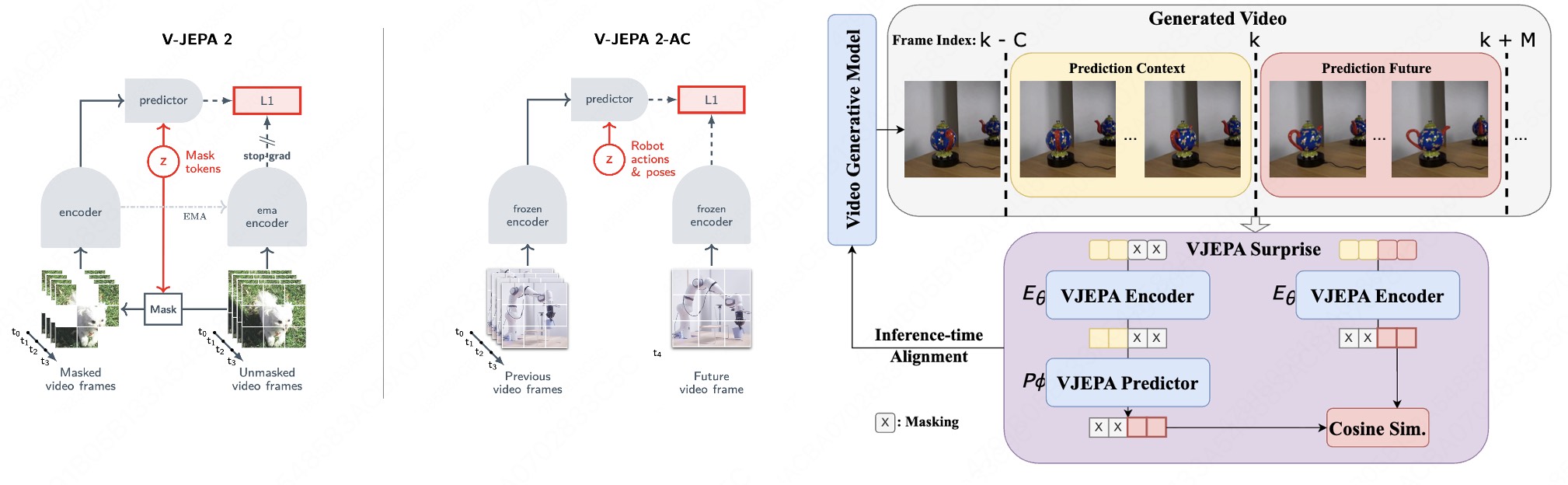
3.4 小结:表征可借,borrowing > 从头学
最值得划重点的是这条趋势的跨模态普适性:它不是图像扩散的专利。语言侧的 continuous DLM 正在走同一条路——ELF「借 frozen T5 contextual embedding」就是这套"借现成 encoder 表征"思想在语言上的极简实例,其中 ELF 的 frozen encoder + 共享 decoder 与本节 (b) 的 RAE 在结构上高度对应(见 §3.2 的对照框,§5 会展开)。从 DINOv2 到 T5,从图像到语言,结论是一致的:
承上启下。§3 走的是"借表征"这条路——把语义这件事外包出去。但还有一条更朴素、更接近问题物理本质的路:连表征都不学,直接吃数据自身的几何结构。下一节我们就从 manifold hypothesis 出发,看 [7][8][9] 如何把数据的低维流形当作一等公民。
4 · 绕开表征:直接利用数据流形的几何结构
前三节一直在「表征」这个层面打转:diffusion 自己学的表征长什么样(§2)、怎么把现成 SSL 表征注进来(§3)。但表征终究是一个间接的抓手——我们真正想要的,是让模型「认识」数据本身的结构。一个自然的问题是:能不能跳过表征这一层,直接把数据的几何结构喂给生成模型?
这条路的底层信念只有一句话——manifold hypothesis(流形假设)。它说:那些看起来住在百万维像素空间里的自然图像、视频,其实只散落在一张维度低得多的「流形」\(\mathcal{M}\) 上。如果这是真的,那么我们大半的建模努力(高维去噪、堆容量、对齐表征)可能都在为「环境维度」(ambient dimension) 买单,而真正该锚定的是那张薄薄的低维曲面。本节梳理三项把流形直接当作一等公民的工作:用流形换容量的 [7]、用流形换预测目标的 [8]、用流形换推理动力学的 [9],最后把它们和语言侧 continuous DLM 的 DSL / ELF 对接起来(§4.6 与 §5)。
4.1 流形假设:高维数据的「真自由度」很低
形式化地说,流形假设断言数据分布 \(p_{\text{data}}\) 的支撑集近似落在一个低维子流形上:
$$ \operatorname{supp}(p_{\text{data}}) \approx \mathcal{M} \subset \mathbb{R}^{D}, \qquad \dim \mathcal{M} = d \ll D. $$这里 \(D\) 是环境维度(如 \(256\times256\times3 \approx 2\times10^5\) 个像素),而内在维度 \(d\) 可能只有几十到几百。直觉上很好理解:一张自然图像的像素之间高度相关——相邻像素几乎相同、纹理重复、物体有刚性约束——所以「合法图像」在像素空间里只占一个测度几乎为零的薄壳。视频更夸张:连续帧之间被光流和物理一致性死死绑住,时间维度几乎没有引入新的自由度。
这件事对 diffusion 有一个直接而深刻的后果。前向加噪 \(x_t = \alpha_t x_0 + \sigma_t \epsilon\) 把数据从流形 \(\mathcal{M}\) 上「推开」到整个 \(\mathbb{R}^D\);而 score function \(\nabla_x \log p_t(x)\) 在低噪声时本质上是一个指向流形的法向投影——它告诉每个偏离流形的点该往哪个方向缩回 \(\mathcal{M}\)。Qing Qu 组在 [1][2] 里讲的「balanced 表征 ~ 充分覆盖数据流形方向、spiky ~ 塌进少数记忆方向」,也可以理解为在描述模型有没有学到这张流形的切空间结构。§4 的工作只是把这个隐含的几何,提到了台前。
4.2 容量视角:流形估计好之后,去噪器可以更简单
从容量角度看,一个自然的问题是:如果数据已经被映射到一个较好的低维 latent 流形上,后面的 diffusion 去噪器是否还必须很大?作者近期的 Multi-Subspace MoE 工作 [7](ICLR 2026)可以看作这条思路的一个例子:先用 VAE 把图像压到 latent 空间,再用由多个浅层 expert 组成的 MoE 去建模不同局部子空间。这里的重点不在于"某个架构本身足够强",而在于它提示了一种取舍——当流形估计承担了更多结构性工作,去噪网络需要表达的函数可能就简单得多(按原论点:VAE 把流形估计好时,一个 2 层 MoE 即可生成 ImageNet 级数据)。

4.3 让去噪模型去「去噪」:x-prediction 与 pixel-space 的回归
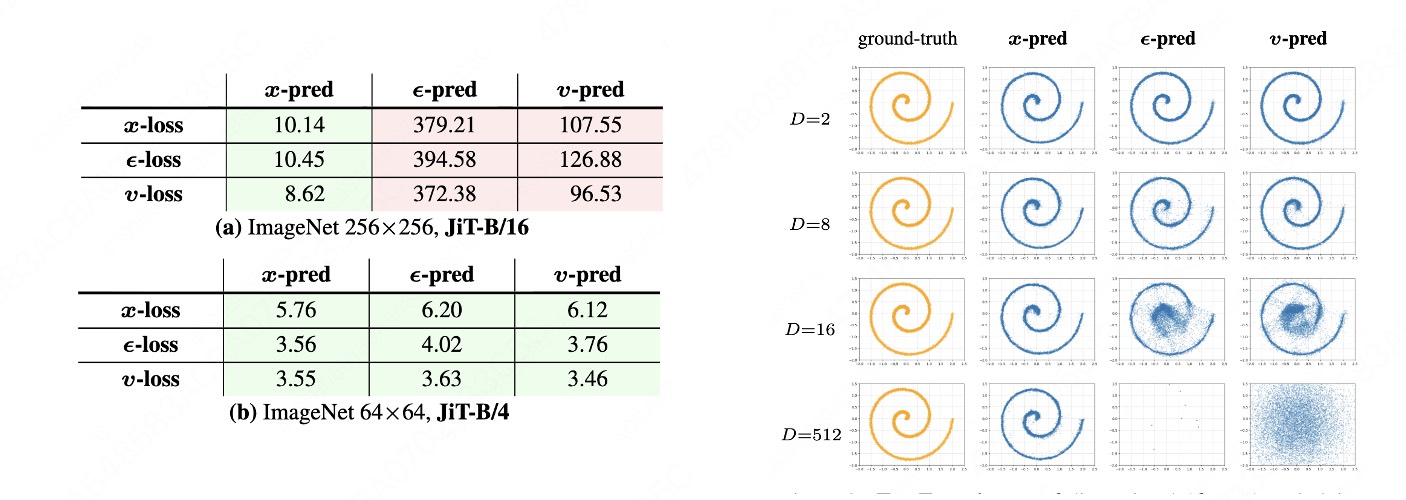
第二项 [8] 把流形思想落到了 diffusion 最核心的设计选择——预测目标上。这是 Kaiming He 组的 Back to Basics: Let Denoising Generative Models Denoise(JiT)。标题本身就是论点:让去噪模型,老老实实去预测干净的数据 \(x_0\),而不是去预测噪声。
回忆 §1 里 diffusion 训练目标的三种等价参数化。给定 \(x_t = \alpha_t x_0 + \sigma_t \epsilon\),网络可以选择回归不同的量:
$$ \underbrace{\mathcal{L}_\epsilon = \mathbb{E}\,\big\| \epsilon_\theta(x_t,t) - \epsilon \big\|^2}_{\text{ε-prediction(预测噪声)}}, \qquad \underbrace{\mathcal{L}_x = \mathbb{E}\,\big\| x_\theta(x_t,t) - x_0 \big\|^2}_{\text{x-prediction(预测干净数据)}}. $$三者在数学上可以互相换算(\(\epsilon = (x_t - \alpha_t x_0)/\sigma_t\)),看似只是重参数化。但在流形视角下,它们的「难度」完全不同:
- 预测 \(\epsilon\):目标是各向同性高斯噪声,填满整个 \(D\) 维环境空间,没有任何低维结构可言。网络被迫在全维度上输出一个高方差、无几何约束的向量。
- 预测 \(x_0\):目标恰好落在低维流形 \(\mathcal{M}\) 上。网络的输出天然被约束到一张薄曲面,回归的「有效自由度」是 \(d\) 而不是 \(D\)。它在做的事情,字面意义上就是「去噪」——把脏的 \(x_t\) 投回干净流形。
正因为 \(x\)-prediction 的目标自带低维流形约束,它比预测高维噪声更直接、更稳定。[8] 的一个反直觉之处在于:靠这个朴素选择,diffusion 可以直接在 pixel space 上 work,而不必先经过 VAE 压到 latent——长期以来人们以为高分辨率必须 latent diffusion,而「让去噪器真的去去噪」让 pixel-space 重新成为可行选项。这也开启了一系列回归 pixel-space 的后续工作。
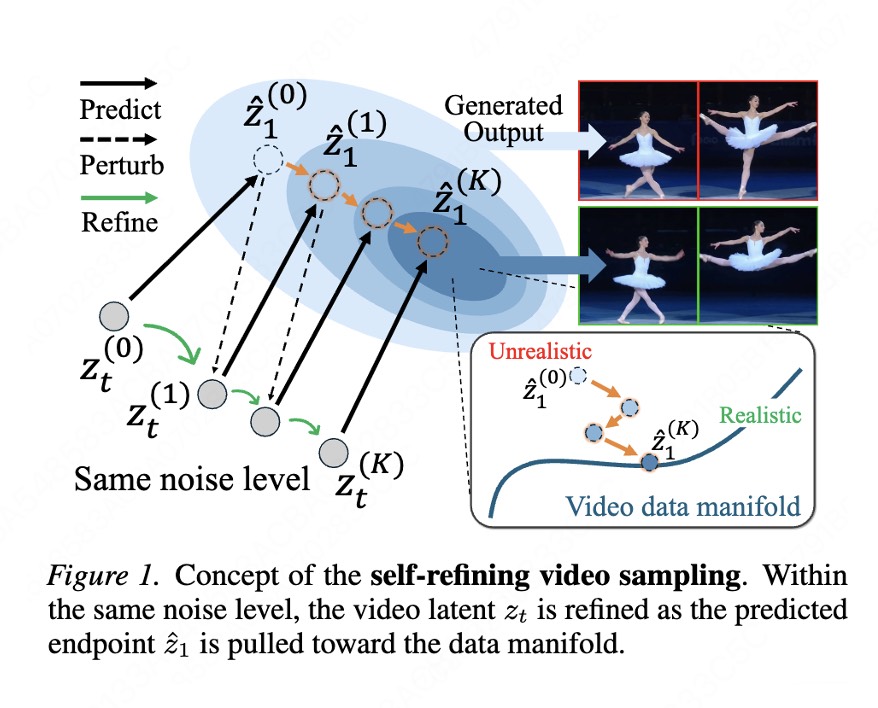
4.4 推理时 predict–perturb:training-free 地 localize 到真实流形
前两项是训练侧的流形利用(换架构、换目标),第三项 [9](Self-Refining Video Sampling)则把流形思想搬到推理侧,而且完全 training-free——不动一行训练代码,只改采样过程。
它的观察是:一个训练好的(视频)生成模型,其单步输出未必精确落在真实数据流形上,往往偏在流形附近的「壳」里。但模型内部其实大致知道流形在哪——它的去噪映射 \(x_\theta(\cdot)\) 可以近似看作一个指向流形的投影(这呼应 §1.3 关于 Consistency Models 的直觉)。于是可以在推理时反复利用这个投影,做一个「预测—扰动—再预测」(predict–perturb) 的迭代:
输入:训练好的去噪器 x_θ,初始样本 x,扰动尺度 σ,迭代步数 R
for r = 1 … R:
x̂ ← x_θ(x, t_r) # predict:把当前样本投向数据流形 M(去噪 = 法向投影)
x ← x̂ + σ_r · ξ, ξ~N(0,I) # perturb:在流形附近注入小扰动,跳出当前局部
# (σ_r 随 r 递减:扰动越来越小,逐步收紧到流形上)
return x # 反复 project→perturb 后,x 逐渐 localize 到真实流形 M
每一次 predict 把样本拉回流形(投影分量),每一次 perturb 在流形附近重新探索(切向分量),随着扰动尺度递减,样本会像退火一样逐渐 localize(收敛、锚定)到真实数据流形上。直觉上这是一个不动点迭代:真实流形上的点是去噪映射的(近似)不动点,反复 project–perturb 会把样本吸到这些不动点附近,从而提升生成结果的真实感与(对视频而言的)物理合理性。整个过程不需要额外训练,纯粹是对「模型已经隐式编码了流形」这一事实的推理时再利用。
4.5 三条流形利用路线 = 三个不同的旋钮
把 [7][8][9] 并排看,会发现它们其实在拧三个完全不同、但指向同一信念的旋钮:
「数据是低维流形」这一个信念
│
┌───────────────────────┼───────────────────────┐
▼ ▼ ▼
[7] 架构 / 容量 [8] 预测目标 [9] 推理动力学
VAE 找对流形 x-prediction predict–perturb
→ 2 层 MoE 即够 预测落在流形上的 x₀ 反复投影+扰动
流形估好 → 去噪更简单 而非填满全空间的 ε 逐渐 localize 到流形
│ │ │
省下的是:模型容量 省下的是:回归自由度 省下的是:训练成本
(training-free)
三者互不冲突、甚至可以叠加:用 [7] 的 VAE 把流形找对、用 [8] 的 x-prediction 让去噪器对齐流形、再用 [9] 在推理时把样本 localize 回流形。共同的反面教材,是那种「在 \(D\) 维环境空间里无脑去噪、靠堆容量硬扛」的粗暴做法——它对数据的低维性视而不见。
4.6 跨到语言:DSL 的 unit-sphere localization 与 ELF 的 x-prediction
到这里,细心的读者应该已经嗅到一股熟悉的味道。本节讲的「直接利用数据流形几何」,正在语言侧的 continuous DLM 上高度对应地复现——只不过对象从图像/视频换成了文本 token 的连续表示。两个最直接的对应(§5 会展开成完整的跨模态对仗):
本节 [9] 的精神是「推理时把样本 localize 到数据流形」。在语言连续扩散里,DSL 把这件事做成了训练/采样的核心机制:它不在欧氏全空间上加噪,而是在单位球面 (unit sphere) 这张几何流形上做 stochastic localization,让几何结构随 SNR 动态涌现。这正是「利用流形 / 几何先验」从图像迁到语言的版本——把「数据住在一张低维曲面上」这个 [7][8][9] 的图像直觉,换成了「语言的连续表示天然适合一个有界球面流形」。(详见 continuous DLM blog 关于 DSL 几何与 stochastic localization 的章节,约 §10。)
本节 [8] JiT 的论点是「预测落在流形上的干净 \(x_0\) 比预测填满全空间的噪声 \(\epsilon\) 更直接、更稳定」。这恰恰是 ELF 在语言连续扩散里做出的同一选择:ELF 采用 x-prediction,让模型直接预测干净的(contextual embedding 形式的)目标,而非噪声——并被验证在全维度上更稳定。图像侧「let denoising models denoise」与语言侧「ELF 用 x-pred 预测干净 contextual target」是同一条原理的两次落地。(详见 continuous DLM blog 关于 ELF x-prediction 的章节,约 §4 C.1:x-pred 全 dim 稳定。)
把 §3 和 §4 一起看,跨模态的对仗就完整了:§3 的「借表征」对应语言侧 ELF「借 frozen T5 contextual embedding」;§4 的「用流形 / x-pred」对应语言侧 DSL 的「unit-sphere localization」与 ELF 的「x-prediction」。一句话——图像扩散这套「利用流形 / 预测干净 x / 推理时 localize」的经验,正在被迁移到语言 continuous DLM 上。下一节(§5)就把这层联系正面展开;想看这套思想在语言上的完整版,可移步 continuous DLM blog(§4 / §10)。
5 · 与 continuous DLM 的联系 —— 图像扩散的经验正被搬到语言上
前面四节(§1–§4)讲的全是图像 / 视频扩散:denoising 天然是 SSL(§1)、扩散自己长出的表征长什么样、何时学坏(§2)、为什么干脆外借现成 SSL 表征以及怎么注入(§3)、以及绕开表征、直接吃数据的低维流形结构(§4)。但如果你最近也在看语言上的连续扩散语言模型(continuous DLM),会有一种强烈的既视感:图像扩散这几年踩出来的两条路——「借表征」和「用流形」——正被平移到语言上。这一节就把这两条暗线接起来。
💡 一句话主题
表征 / 流形这套图像扩散的经验,正在被搬到语言 continuous DLM 上。图像端「借 frozen SSL 编码器的表征」对应语言端 ELF「借 frozen T5 的 contextual embedding」;图像端「用 x-prediction、用数据流形几何」对应语言端 ELF 的 x-prediction 与 DSL 的 unit-sphere stochastic localization。两边解决的是同一个病:不要让模型把算力浪费在重新学一套数据已经免费给你的几何结构上。
语言端这条线的细节,我们在另一篇里展开讲(ELF / Cola-DLM / DSL 的 landscape、训练 pipeline、采样网格、跨家族对比):continuous DLM blog。本节只做「图像 ↔ 语言」的对位翻译。
5.1 「借 SSL 表征」(§3) ↔ ELF「借 frozen T5 表征」
§3 的核心动机是:扩散模型自己自发学好表征很难、很玄(§2 的单峰动力学 [1] 和 balanced/spiky 谱 [2] 已经说明这个「度」难把握),那不如直接站在 SSL 巨人的肩上,把一个在海量数据上预训练好、表征已经成形的 frozen 编码器(MAE / DINOv2)的特征接进来。VA-VAE [3] 在 VAE latent 层对齐、REPA [4] 在 DiT 中间层加 alignment loss、RAE [5] 干脆把 SSL 编码器的潜空间当成扩散空间,训练 decoder 与在该空间上的 diffusion——这是一条从底层到中层的「注入谱」。
ELF(Embedded Language Flows)在语言上做的事,本质就是这条谱在文本模态的极简落点。它把去噪过程从离散 token 网格搬到一个连续坐标系里,而这个坐标系不是端到端学出来的,是外借的——直接用 frozen 的 T5-small encoder 输出的 contextual embedding(512 维)当现成的「语义几何」。tensor 流是这样的:
input_ids: [B, L] ← 离散 token(每个 0~32127)
↓ T5-small frozen encoder(不学!≈ 图像里的 frozen MAE/DINOv2)
contextual emb: [B, L, 512] ← 每个位置一个 512-d 向量 = 借来的「语义坐标系」
↓ + 噪声 z = t·x + (1−t)·ε
z_t (noisy): [B, L, 512] ← ELF 的 Flow Matching 就在这个连续 tensor 上去噪
↓ ~32 步 Euler 迭代(学 transport 动力学)
clean emb: [B, L, 512] ← 终点 ≈ 干净的 contextual embedding
↓ shared decoder head(仅 t=1 这一步:512 → 32128 logits)
output tokens: [B, L] ← per-position argmax
这张图和 §3(b) 的 RAE [5] 在结构上高度对应:frozen 编码器给坐标系 + 一个共享 decoder 做最后一跳,中间扩散网络专心在这个借来的空间里学 transport。区别只在模态——RAE 借的是 DINOv2 的视觉潜空间,ELF 借的是 T5 的文本 contextual embedding。两者的 framing 高度一致,可以写成同一句话:
$$ \underbrace{\text{frozen encoder } E_{\text{SSL/T5}}}_{\text{语义几何 · 不学}} \;\circ\; \underbrace{\text{diffusion transport } v_\theta}_{\text{动力学 · 只学这个}} \;\circ\; \underbrace{\text{light / shared decoder } D}_{\text{最后一跳}}. $$把「语义几何」和「transport 动力学」在架构上分离,正是 §3 那条「borrowing > 从头学」原则的语言版本:图像端解决的是「重建好但 latent 语义差」的 dilemma(VA-VAE)、「DiT 自发学表征太慢」(REPA「easier than you think」);语言端 ELF 解决的是过去 continuous DLM 那种「embedding 和 diffusion 互相依赖、鸡生蛋」的早期训练不稳定——把表征学习从 loop 里拿掉,训练算力全押在 transport 上。
🔑 takeaway(5.1)
ELF =「在语言上借 frozen 表征」的极简实现,是 §3 图像注入谱(VA-VAE / REPA / RAE)跨模态迁移到文本的直接产物。共同公式:frozen encoder(语义几何)+ diffusion(transport)+ light decoder(落点),三件事架构解耦,模型不再重复学一套数据已经免费提供的语义坐标系。
5.2 「利用流形 / x-prediction」(§4) ↔ ELF 的 x-pred + DSL 的 unit-sphere localization
§4 讲的是另一条主线:绕开「学表征」,直接利用数据本身的低维流形结构。两个最干净的体现是——(i) Kaiming 的 x-prediction(JiT [8]):既然干净数据落在低维流形上,那就让网络直接预测低维的干净 x,而不是预测高维全空间的噪声 \(\varepsilon\) / velocity \(v\);(ii) 推理时反复 predict-perturb [9] 会逐渐 localize 到真实数据流形。语言端这两点也都有清晰的对位。
5.2.1 x-prediction:语言端和图像端选了同一个答案
三种 parameterization 在数学上等价:
$$ x\text{-pred: } \hat x_\theta(z_t,t)\approx x_0,\qquad \varepsilon\text{-pred: } \hat\varepsilon_\theta(z_t,t)\approx \varepsilon,\qquad v\text{-pred: } \hat v_\theta(z_t,t)\approx \tfrac{\partial z_t}{\partial t}, $$但训练信号完全不同。\(x\)-pred 的 target 是固定的干净数据点 \(x_0\)(落在低维流形上,不随 \(t\) 漂移);而 \(\varepsilon\)-pred 的 target 是一个填满高维空间的各向同性 Gaussian(与流形无关);\(v\)-pred 的 target 则随 schedule 把 \(x_0\) 与 \(\varepsilon\) 混合。无论哪种,模型都被迫去建模高维全空间方向上的分量——维度一高就崩。这正是 §4 里 JiT [8]「让去噪模型老老实实去噪(预测 x)」的论点。
ELF 在语言上做了完全相同的选择:网络直接输出 clean embedding \(\hat x\),velocity 只是事后由 \(v=(\hat x - z_t)/(1-t)\) 换算出来。ELF 论文的消融(App C.1)按原论点给出的结论是:在不同 encoder 维度(512 / 768 / 1024)下,x-pred 在全维度都稳定,而 \(\varepsilon\)-pred 全维度崩、\(v\)-pred 维度越高越差。论文给的解释和 §4 一字不差——clean 文本在 embedding 空间里也是一个低维流形,x-pred 预测的就是这个流形上的点,而 \(\varepsilon\)-pred 要建模高维 Gaussian,更难。
💡 同一条流形论证,两个模态各说了一遍
图像(JiT [8]):像素 / latent 上的干净图落在低维流形,预测低维 x 比预测高维 ε 直接 → pixel-space 也能 work。
语言(ELF App C.1):T5 contextual embedding 上的干净文本落在低维流形,x-pred 全维稳定、ε-pred 全崩。
两边的因果链相同:数据有低维流形结构 ⇒ 预测「落在流形上的干净目标」比预测「填满高维空间的噪声」更省力、更稳。「continuous DLM 的关键不是『连续』,而是『x-prediction』」这句话,本质就是 §4 流形论点的语言版。
5.2.2 DSL:把「利用流形几何」做成 unit-sphere stochastic localization
§4 的第二个体现是 predict-perturb [9]——推理时反复「预测 - 扰动」会逐渐把样本 localize 到真实数据流形上,是一个 training-free 的流形利用技巧。语言端把这个「localization」思想做成了一个完整框架:DSL(Discrete Stochastic Localization)。DSL 把每个离散 token 嵌到一个 unit-sphere(单位球面)上,在这个连续球面几何里做 stochastic localization。它和 ELF 在「表征哲学」上的关键区别恰好对应 §3 vs §4 的分野:
图像扩散 (§3 / §4) 语言 continuous DLM
───────────────── ───────────────────
借 frozen MAE/DINOv2 表征 (VA-VAE/REPA/RAE) ⇄ ELF:借 frozen T5 contextual embedding
学 端到端学一个 latent (VAE) ⇄ Cola-DLM:联合训练一个 text VAE latent
涌现 随去噪过程自然组织的几何 (§2 单峰动力学) ⇄ DSL:unit-sphere 几何随 SNR coarse-to-fine 涌现
DSL 最漂亮的地方在于:它的表征几何既不是预先外借的(像 ELF),也不是学一个固定 latent(像 Cola),而是随信噪比 SNR 从粗到细动态「长出来」。同一个 token 在低 SNR 时在球面上弥散(只有最粗的语义判断),SNR 升高后概率质量逐步集中、最终落到球面上的某个锚点(收敛到一个具体词)——这是一种层次化细化(coarse-to-fine refinement)。这恰好呼应了 §2 里 [1] 描述的「表征质量随扩散时间 \(t\) 的单峰动力学」与 §4 [9] 的「逐步 localize 到真实流形」:几何不是给定的,是沿噪声轴自然组织出来的。
🔑 takeaway(5.2)
§4 的「直接用低维流形」在语言上裂成两半:x-prediction(ELF)= 预测落在流形上的干净目标而非高维噪声,与 JiT [8] 是类似论证;unit-sphere stochastic localization(DSL)= 在球面几何上做 localization、几何随 SNR 涌现,与 predict-perturb [9] 是类似直觉。语言端不是另起炉灶,而是把图像扩散验证过的流形经验迁移过来。详见 continuous DLM blog。
6 · Summary —— 四条线,一个共同主题
从头回顾,这篇 blog 其实是一条逻辑递进的链子,每一节回答上一节逼出来的问题:
§1 SSL objective denoising 本身就是自监督任务 → diffusion 训练免费附带表征
│ «那它自己学出来的表征长什么样?»
▼
§2 自发表征 中间层可作下游表征;但「学好」靠泛化——
单峰动力学 [1] / balanced vs spiky 谱 [2];不泛化则塌成记忆
│ «自发学好这么玄,能不能不自己学?»
▼
§3 注入表征 借 frozen SSL 编码器:VA-VAE [3] / REPA [4] / RAE [5] / V-JEPA2 guidance [6]
│ «连表征都不学,直接吃数据的几何行不行?»
▼
§4 利用流形 manifold hypothesis:x-prediction (JiT [8]) / manifold-aware 架构 [7] / inference localize [9]
│
▼
§5 跨模态迁移 §3 → ELF「借 frozen T5 表征」;§4 → ELF x-pred + DSL unit-sphere localization
── 同一套经验从图像搬到语言 continuous DLM ──
把这四条线(SSL objective → 自发表征 → 注入表征 → 利用流形)放在一起看,会浮出一个共同主题:
🔑 共同主题
让模型少做无用功,多用数据结构先验。
五年前 MoCo / SimSiam / MAE / DINOv2 这条 SSL 暗线证明了「数据自己就能教出好表征」;今年的生成模型则把这件事推到极致——凡是数据已经免费提供的结构(语义几何、低维流形、噪声轴上的层次),就不要再花训练算力去重学一遍。借表征(§3 / §5.1)是把「数据有什么语义」这个问题外包给 frozen 编码器;用流形(§4 / §5.2)是把「数据有什么几何」这个先验直接写进 parameterization(x-pred)和状态空间(unit-sphere)。两条路都是同一种「省」——把算力从「重学结构」省下来,全押在「学动力学 / transport」上。
但正如原 blog 所说,今年这套东西虽然开始脱离粗暴方式、利用数据特性,结构构造还很 rough,有大量 work 空间。两个方向尤其值得继续:
- 更原则化的流形 / 表征构造。现在「借哪个编码器、对齐到哪一层、流形怎么参数化(球面?低维 latent?随 SNR 涌现?)」大多还是工程经验和 ablation 试出来的(ELF App C.1 选 x-pred、DSL 选 unit-sphere)。§2 的可解释性工作 [1][2] 暗示「表征质量 / balanced 谱」本身就是一个可量化的泛化指标——如果能把它变成训练时可优化的目标或可设计的几何先验,而不是事后诊断,注入与利用就能从「试」走向「设计」。
- 跨模态迁移。§5 已经显示图像端的经验(借表征 / x-pred / 流形 localization)大体平移到了语言(ELF / DSL)。反过来,语言端的 frozen-encoder 解耦(把语义几何彻底踢出训练 loop)、DSL 的「同一网络支持一整族 per-token SNR path、几何随 SNR 涌现」这类干净 framing,也可能反哺图像 / 视频扩散。「表征 / 流形」很可能是一个模态无关(modality-agnostic)的设计语言——这正是把这两篇 blog(图像端本文 + 语言端 continuous DLM blog)放在一起读的意义。
💡 一句话收尾
过去我们让扩散模型在高维空间里大海捞针;现在我们开始告诉它:「数据的语义在这(借表征),数据的几何长这样(用流形),你只管学怎么走(transport)。」 五年前 MoCo 种下的那颗「数据自己能教模型」的因,正在 2025 的生成模型上结成果——而它结果的方式,在图像和语言上惊人地一致。
References
- [1] Understanding Representation Dynamics of Diffusion Models via Low-Dimensional Modeling. Qing Qu 组。扩散模型表征质量随扩散时间呈单峰动力学;缺乏泛化(陷入训练集记忆)时,这一单峰的优秀表征结构会逐步消失。(本文按原论点引用,不附加论文未给出的定理 / 数字。) · arXiv 2502.05743
- [2] Generalization of Diffusion Models Arises with a Balanced Representation Space. Qing Qu 组。训练不足时表征谱呈 spiky(集中于少数方向);训练良好的模型表征谱 balanced,充分覆盖数据分布特征、泛化更好。(按原论点引用。) · arXiv 2512.20963
- [3] VA-VAE — Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models. 把 latent diffusion 的 VAE latent 与 frozen SSL 特征(MAE / DINOv2)对齐,平衡重建与生成、让 latent 富含语义。 · arXiv 2501.01423
- [4] REPA — Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. Saining Xie 组。在 DiT 中间层加 alignment loss,把 hidden 表征拉向 DINOv2 特征,显著加速 DiT 训练。 · arXiv 2410.06940
- [5] RAE — Diffusion Transformers with Representation Autoencoders. 用冻结的预训练 SSL 表征 encoder 配一个训练的 decoder 构成 representation autoencoder,并在该 representation latent 上训练 diffusion / DiT。(原 blog 此条标题曾与 [4] 重复,此处按正式题名修正。) · arXiv 2510.11690
- [6] Inference-time Physics Alignment of Video Generative Models with Latent World Models (V-JEPA2). 把生成视频与真实视频在 V-JEPA2 的表征流形上对齐,作为推理时的「真实性 / 物理合理性」裁判,提升物理合理性。 · arXiv 2601.10553
- [7] Multi-Subspace Multi-Modal Modeling for Diffusion Models: Estimation, Convergence and Mixture of Experts. Ruofeng Yang 等(ICLR 2026)。论点:若 VAE manifold 估计得好,所需模型容量大降——一个 2 层神经网络的 Mixture-of-Experts 架构即可生成 ImageNet 级数据。(按原论点引用,不附加论文未给出的定理 / 数字。) · arXiv 2601.01475
- [8] JiT — Back to Basics: Let Denoising Generative Models Denoise. Kaiming He 组。当数据落在低维流形上时,直接预测低维干净 \(x\)(x-prediction)比预测高维噪声更直接,即使在原始 pixel space 也能 work。 · arXiv 2511.13720
- [9] Self-Refining Video Sampling. 推理时反复「predict-perturb」,样本逐步 localize 到真实数据流形——一个 training-free 的流形利用技巧。 · arXiv 2601.18577
SSL / 基础论文(引子与 §1 提到)
- MoCo — Momentum Contrast (He et al. 2019) · arXiv 1911.05722
- SimSiam — Exploring Simple Siamese Representation Learning (Chen & He 2020) · arXiv 2011.10566
- BYOL — Bootstrap Your Own Latent (Grill et al. 2020) · arXiv 2006.07733
- MAE — Masked Autoencoders Are Scalable Vision Learners (He et al. 2021) · arXiv 2111.06377
- DINOv2 — Learning Robust Visual Features without Supervision (Oquab et al. 2023) · arXiv 2304.07193
- Consistency Models (Song et al. 2023) · arXiv 2303.01469
- V-JEPA — Revisiting Feature Prediction for Learning Visual Representations from Video (Meta 2024) · arXiv 2404.08471
- V-JEPA 2 — Self-Supervised Video Models Enable Understanding, Prediction and Planning (Meta 2025) · arXiv 2506.09985
相关的语言端 continuous DLM 工作(ELF: Embedded Language Flows、DSL: Discrete Stochastic Localization、Cola-DLM)在配套的 continuous DLM blog 中详细展开,其论点已在 §5 中按原作者表述引用。